Huggingface BERT 모델(BertModel, BertForSequenceClassification, BertForMaskedLM, BertForTokenClassification)
BERT 모델 사용하기
허깅페이스에서 BERT 모델을 불러와서 사용할 때 목적에 맞게 다양한 함수를 불러온다.
예를 들어, STS(Semantic Textual Similarity) task에서 두 문장이 비슷한지 아닌지를 분류하는 문제를 풀기 위해, CLS토큰을 사용하여 학습을 할 것이다. BertForSequenceClassification를 사용하면 “BERT모델의 CLS토큰에 분류를 위한 Linear모델을 추가한 모델"을 불러올 수 있다.
from transformers import BertForSequenceClassification
model = BertForSequenceClassification('klue/bert-base', num_labels=1)
또는 BERT의 pre-training방법중 하나인 MLM을 수행하기 위해 BertForMaskedLM을 사용하면 쉽게 모델을 불러올 수 있다.
BertModel
BERT 기본 모델을 불러오려면 역시 BertModel를 사용 해야 할 것이다.(또는 AutoModel)
from transformers import AutoModel # 자동으로 Bert모델 인식을 지원한다.
model = AutoModel.from_pretrained('klue/bert-base')
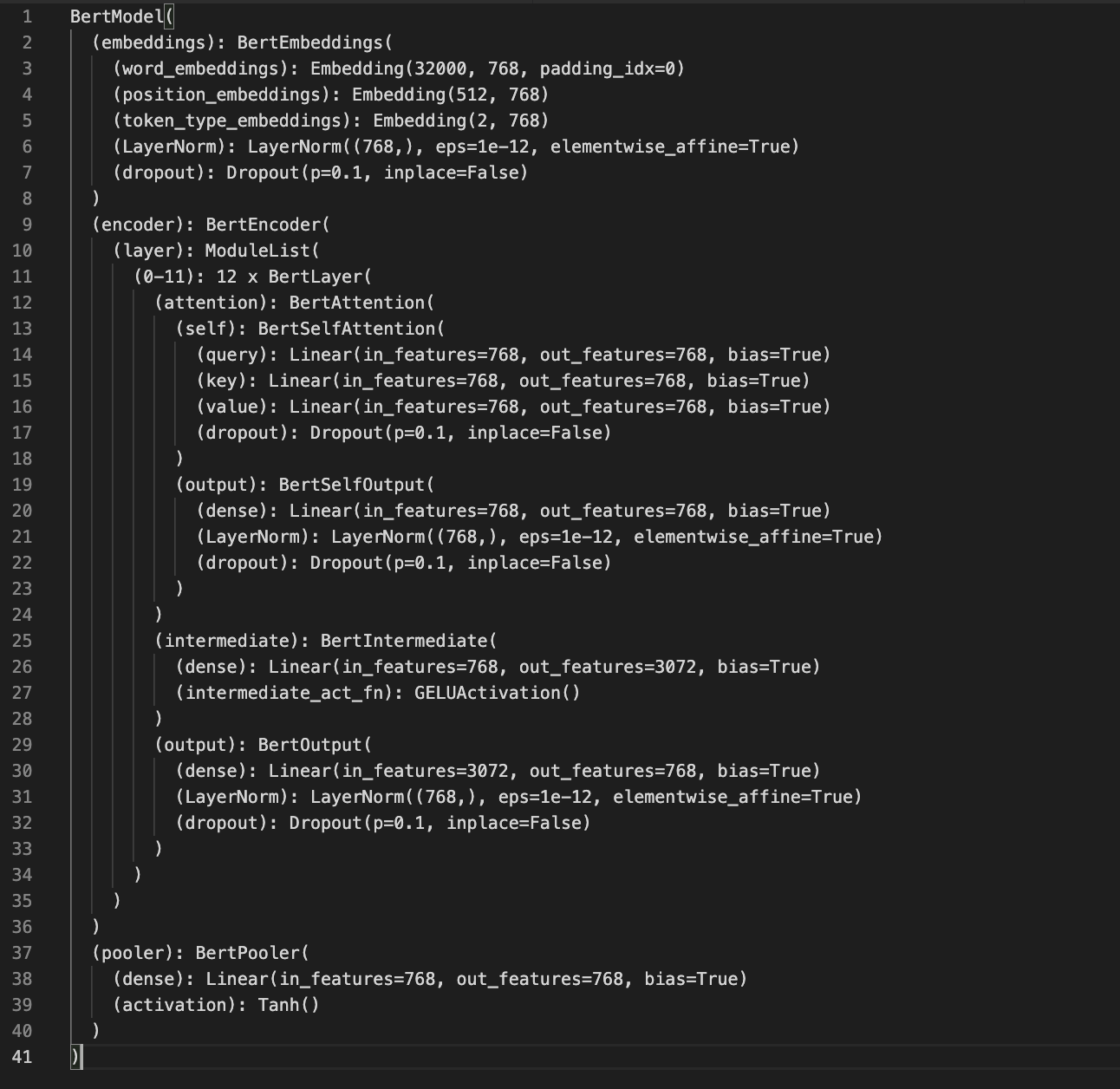
모델을 출력해보면, 모델 구조를 자세히 볼 수 있다. BERT 모델은 embedding layer와 encoder layer로 이루어져 있다고만 알고 있었는데, 마지막에 pooler layer가 추가된 구조를 볼 수 있다
더 자세히 보기위해 모델의 출력을 살펴봤다.
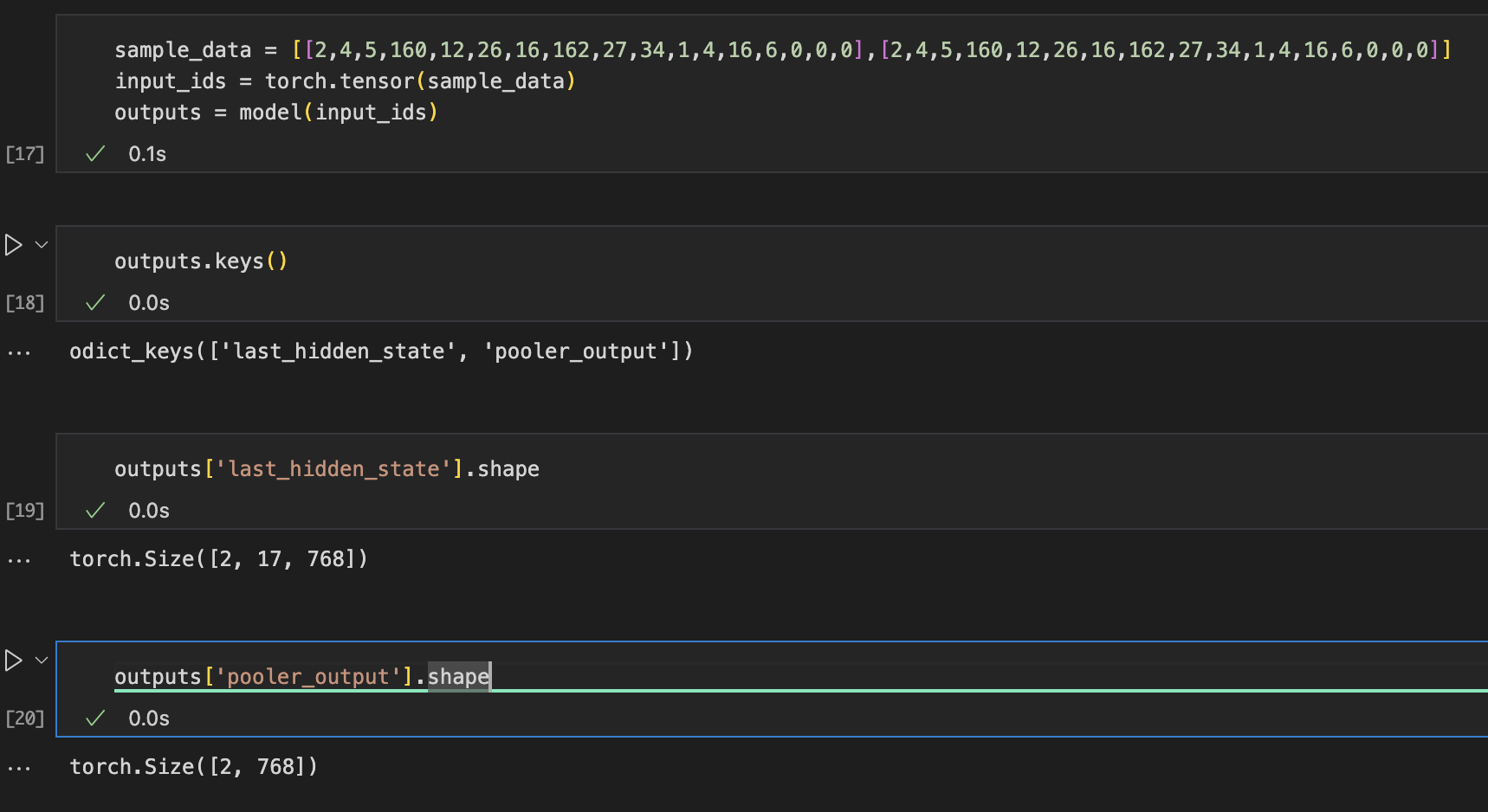
모델의 output으로 두 가지가 나오는데,last_hidden_state가 바로 encoder layer의 출력값에 해당하며 각 토큰마다 가지는 결과값일 것이다.(Batch_size, Sequence_length, hidden_emb)pooler_output은 모델의 마지막에 있던 pooler layer의 출력값에 해당할 것이다. CLS토큰의 출력값과 같은 크기를 가진다. (Batch_size, hidden_emb)
그렇다면 pooler_output과 last_hidden_state[:,0](CLS token)는 같은 값일까?
BertModel의 코드를 자세히 보면 알 수 있는데, CLS 토큰에 Linear모델을 하나 추가한 출력값인듯 하다.

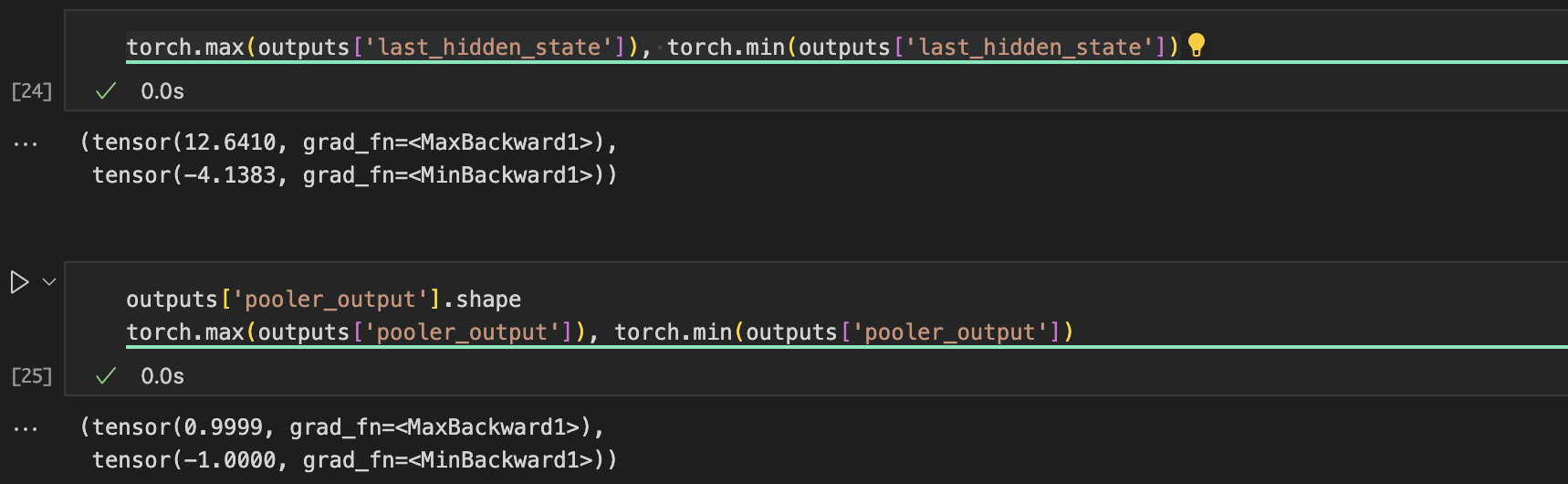
간단하게 max, min값을 출력해보면 값의 범위가 다른 것을 확인할 수도 있다. (Tanh때문에)
참고로 pooling의 방식은 여러가지 방법이 있다. 위의 예시처럼 CLS 토큰만 사용할 수도 있고, 모든 토큰(일부 토큰)의 평균(Mean Pooling), 가장 큰 값을 가지는 토큰의 출력값(Max Pooling) 등이 있다.
참고링크(sentence_transformers)
BertForSequenceClassification
BERT모델의 last_hidden_state에서 CLS토큰에 Linear모델을 추가하면, 간단하게 분류모델을 만들 수 있다. 위에서 BERT모델의 pooler_output과 비슷한 방식일 것이다.
model = transformers.AutoModelForSequenceClassification.from_pretrained('klue/bert-base', num_labels=1)
모델을 출력하면,Some weights of BertForSequenceClassification were not initialized from the model checkpoint at klue/bert-base and are newly initialized: ['classifier.weight', 'classifier.bias']라는 문구가 나오는데, 마지막에 추가된 classifier모델의 가중치는 학습된 파라미터가 아니라는 뜻
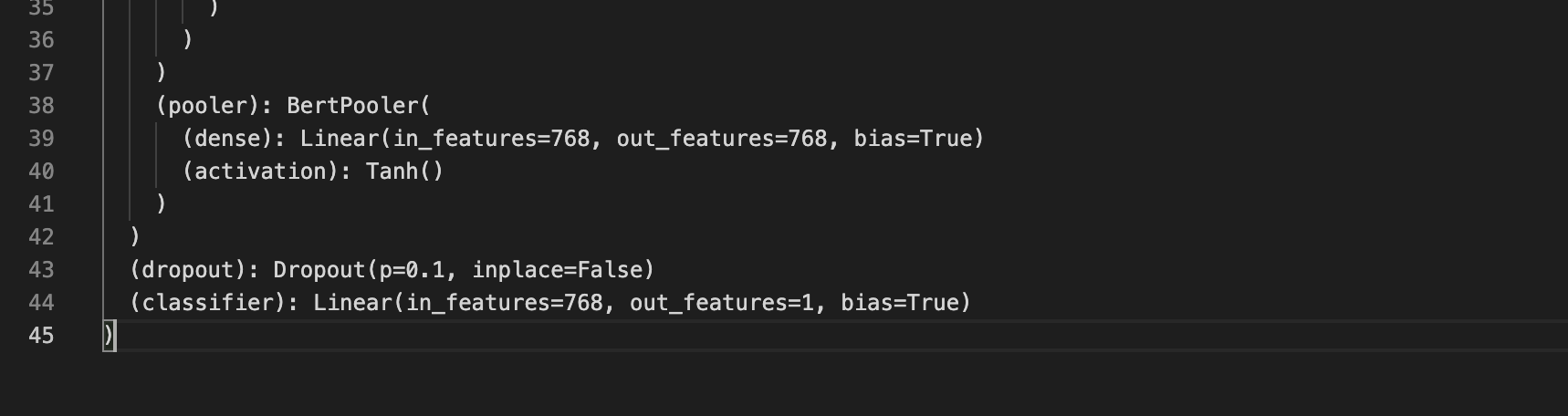
모델의 마지막 부분을 보면, BERT 모델의 pooler_output에 Linear모델(Classifier)이 하나 더 추가된 것을 볼 수 있다. 이때 출력되는 값의 shape은 모델을 정의할 때 num_labels=1에 의해 1로 정의된다.
그럼 CLS토큰에 두 개의 linear model을 달아서 분류 모델을 만든다는 뜻인데, CLS토큰에 바로 classifier를 달아서 사용할 수는 없을까?
BertModel과 마찬가지로 샘플데이터를 넣어 output를 확인해봤다. (이때 input과 label를 모델에 함께 넣을 수도 있음)
# 모델의 input으로 label도 넣을 수 있다.
output = model(input_ids, labels=labels)
print(output.keys()) # ['loss','logits']
print(output['logits']) # tensor([[0.3268], [0.3268]], grad_fn=<AddmmBackward0>)
print(output['logits'].shape) # torch.Size([2, 1])
print(output['loss']) # tensor(1.6264, grad_fn=<MseLossBackward0>)
print(output['loss'].shape) # torch.Size([])
classifier에 의한 출력값은 logits으로 출력된다.
추가적으로 label을 동시에 넣으면, loss값도 계산해준다. (그냥 logits와 label를 계산해서 loss를 구할수도 있음)
criterion = nn.MSELoss()
loss = criterion(output['logits'], labels) # output['loss']와 동일
BertForMaskedLM
(writing)
BertForTokenClassification
(writing)
Reference
- https://github.com/huggingface/transformers/blob/dacd34568d1a27b91f84610eab526640ed8f94e0/src/transformers/models/bert/modeling_bert.py#L468
- https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html?highlight=crossen#torch.nn.CrossEntropyLoss
- https://github.com/UKPLab/sentence-transformers/blob/master/sentence_transformers/models/Pooling.py