[논문리뷰] Attention is all you need #1
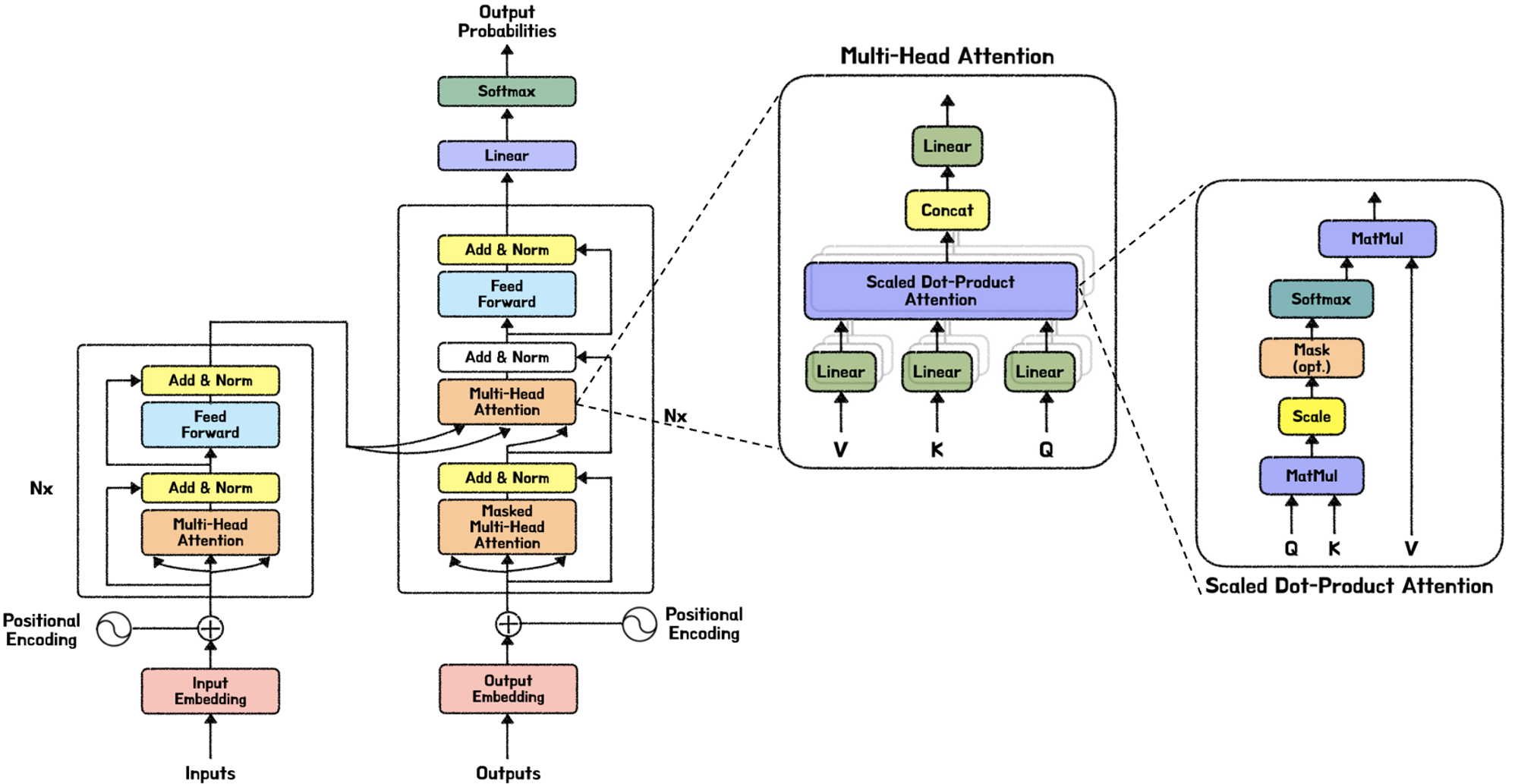
워드 임베딩
각 단어들은 Word2Index를 통해 정수인코딩을 하고, 그 정수값을 임베딩 벡터로 변환한다.
이때 논문에서 임베딩dim 은 512이다.
PE(positional encoding)
트랜스포머 이전에는 RNN모델을 많이 사용했다. 순차적으로 문장을 처리하기 때문에, 계산유닛이 많아도 앞에서부터 하나씩 처리한다. 결국 연산속도가 매우 느리다.
트랜스포머는 문장을 병렬적으로, 한번에 처리한다. 병렬적으로 한번에 처리한다는 것은, 단어의 위치를 알 수 없다는 뜻이다. 따라서 PE를 통해 위치순서를 나타낼 필요가 있다.
- 모든 PE값은 시퀀스의 길이나 값에 관계없이 동일한 식별자를 가져야한다.
- 모든 PE값은 너무 크면 안된다. 워드 임베딩 값이 상대적으로 작아지게된다.
PE를 위한 sin, cos함수 - [-1, 1]사이를 주기적으로 반복하기 때문에 긴 문장에서도 위치 벡터값이 너무 커지지 않으면서, 너무 미미한 차이를 보이지도 않는다.
PE는 단어벡터와 같은 차원의 벡터값이다. 따라서 벡터차원만큼의 주기함수 차원을 가지게 되고, 모든 주기함수의 주기 공배수가 되지 않는 이상 값이 겹치지 않는다.
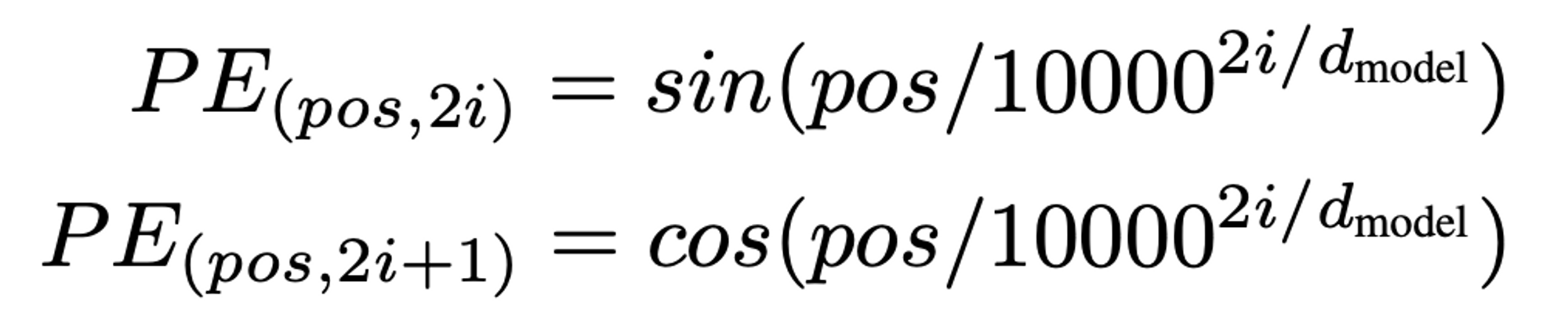
 pos는 각 단어인덱스, i는 벡터인덱스
워드임베딩과 PE의 연산 -> concat이 아니라 summation연산을 사용한다. concat을 사용할 경우 PE역시 자체 차원을 가지게 된다. 따라서 의미가 섞이지 않지만, 비용문제가 발생한다.
summation의 경우 정보가 뒤섞이는 문제가 발생하지만, 단어의미정보가 충분히 유지된다.