[논문리뷰] Attention is all you need #2
Attention, Self-attention
일반적으로 어텐션이란, 입력값에서 중요한 단어들에 더 집중할 수 있도록 한다.
문장을 병렬적으로 처리하기 때문에 속도가 비교적 빠르다.
RNN구조에서는 순차적으로 값을 확인하기 때문에 gradient vanishing/exploding문제가 발생하게 된다.
Self-attention
같은 문장 내에서 단어들 간의 관계를 나타낸다. attention의 입력값은 Q,K,V
Q,K,V
어텐션의 목표는 value의 weighted sum을 구하는것이고, 각 가중치는 Q,K가 얼마나 유사한지에 따라 결정된다.
Query - 소스벡터, 유사도를 계산하는 값
Key - 타겟벡터, 유사도를 계산하는 값
Value - key에 해당하는 정보로 값을 계산, 최종 출력계산에 사용
각각의 값은 인풋이 Linear연산을 거쳐서 구한다. - 벡터의 차원을 줄여준다.
Q.size = n x d_K
K.size = m x d_K
V. size = m x d_V
Z.size = n x d_V
왜 실습에서는 3차원이지? -> 각 단어의 갯수만큼 연산하므로 n_Q, n_K, n_V가 존재
Q, K 의 dimension은 동일해야함
n_batch가 의미하는 것????? - data의 개수, ‘문장’의 개수
dim_V의 값은 정해져있지 않다. 어차피 Linear연산을 마지막에 한번 더 수행하여 z를 얻는다.
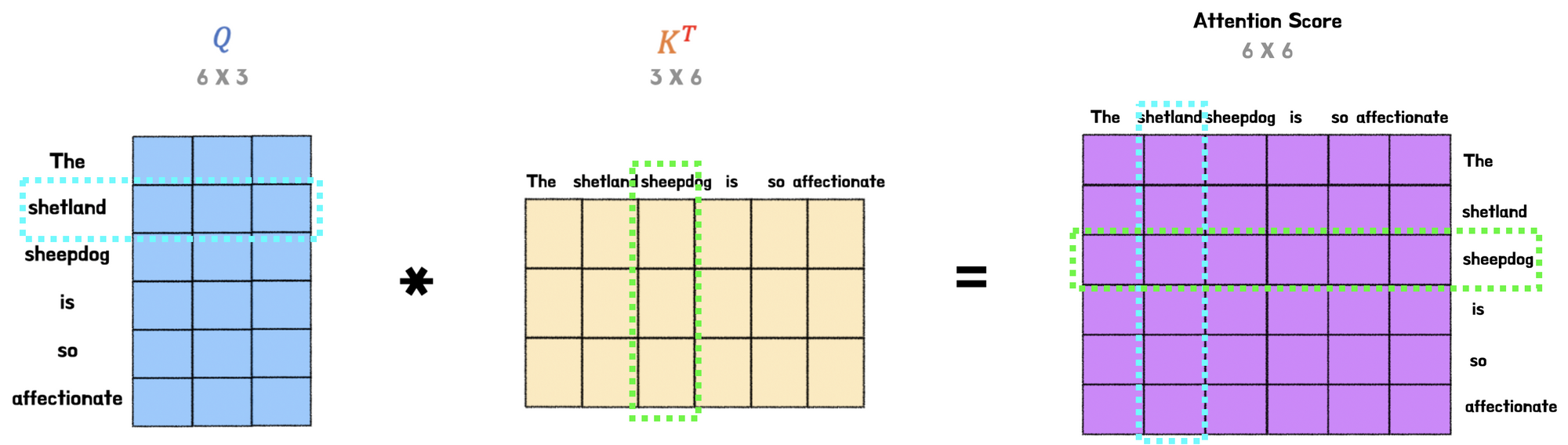
Attention score
–>
코사인 유사도 공식은 A,B가 유사할 수록 1, 다를 수록 -1에 가까워진다. 이때 A*B를 L2norm의 곱으로 스케일링 해서 값을 구한다.
attention score의 차원은 결국, batch_Q x batch_n 의 사이즈. 각각 대응 하는 단어의 갯수의 곱만큼 score행렬을 만들어야한다.

Scaling & Softmax
Q*K dot product의 특성상, 문장길이 dk가 커질수록 더 큰 값을 가지게 되고, softmax에 넣게 되면, 큰값만 살아남는 현상이 발생, 따라서 값이 작으면 gradient vanishing으로 이어질 수 있다. 따라서 스케일링으로 값을 유사하게 맞춰주는 효과 -> 여기서 dk는 n_K인가?? -> 왜 dk가 커질수록 더 큰값을 가지나??
마지막으로 softmax를 거친 값에 Value를 dot product하면 self-attention값이 구해진다.
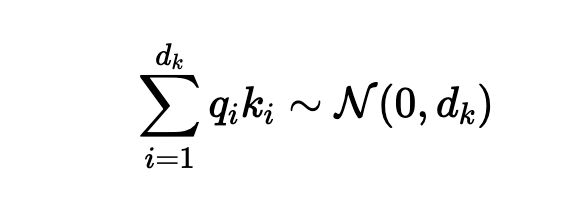
 Q,K이 각각 i.i.d N(0,1)라고 가정하면, 위와같은 분포를 보인다. 따라서 sqrt(dk)로 나눠서 N(0,1)로 다시 조정하는 역할을 한다.
Multihead
multihead를 하는 이유 - 각각의 attention는 토큰 간의 관계(유사도)를 통해 어텐션을 구하고 종속성을 계산하며, 각각의 head는 다른 유형의 종속성을 가지게 된다.(문장타입에집중, 관계에 집중, 명사에집중, 강조에 집중)